Time analyses
The next section of the template produces analyses and outputs related to time, such as epidemic curves.
Basic epidemic curve
The first half of this code chunk (epicurve) is about setting-up the data for the epidemic curves.
First, the function incidence() counts the number of cases for each week, by date_of_onset. It stores this information in the object inc_week_7. Read more about incidence() in the Help pane.
Second, the theme elements are set that ggplot() will use when plotting the epidemic curves (you can read more about ggplot() and theme elements in the Advanced R Basics page). This includes the angle and placement of x-axis label text, having no title in the legend, and setting colors and type for x and y gridlines.
Third, the text labels for the x and y axes, title, and subtitle (subtitle automatically using the reporting_week defined at the top of the template). These are stored in the object epicurve_labels.
It is necessary to use the “full name” of variables for this to work correctly - this means date_of_onset should be listed in incidence() as linelist_cleaned$date_of_onset.
# This code creates case counts for each week of your outbreak, overall
# As with aweek, you can change the start of your week to e.g. "Sunday week"
inc_week_7 <- incidence(linelist_cleaned$date_of_onset, interval = "Monday week")
# this sets the theme in ggplot for epicurves
epicurve_theme <- theme(
axis.text.x = element_text(angle = 45, hjust = 1, vjust = 1),
legend.title = element_blank(),
panel.grid.major.x = element_line(color = "grey60", linetype = 3),
panel.grid.major.y = element_line(color = "grey60", linetype = 3)
)
# This sets the labels in ggplot for the epicurves
epicurve_labels <- labs(x = "Calendar week",
y = "Cases (n)",
title = "Cases by week of onset",
subtitle = str_glue("Source: MSF data from {reporting_week}")
) In this next part of the chunk, the plot of the epidemic curve is finalized and displayed.
The plot() function used here is from the package incidence, not the base R plot() function. This one uses ggplot() and so has different syntax and structure. As with ggplot(), layers of the graphic are added sequentially using the + symbol at the end of each sub-command.
In the example below, the weekly count data from inc_week_7 are plotted first, then miscellaneous settings are specified: the y-axis origin is set, the labels, and finally the theme parameters. All of these elements are stored in the object basic_curve, which is finally run to display the plot.
For some functions, it is necessary to use the “full name” of variables - for example when using incidence(), date_of_onset should be listed as linelist_cleaned$date_of_onset. Otherwise you may get an error such as “object ‘date_of_onset’ not found”.
# plot your epicurve as a ggplot (incidence::plot is different to base::plot)
basic_curve <- plot(inc_week_7, show_cases = TRUE, border = "black", n_breaks = nrow(inc_week_7)) +
scale_y_continuous(expand = c(0, 0)) + # set origin for axes
# add labels to axes and below chart
epicurve_labels +
# change visuals of dates and remove legend title
epicurve_theme
# show your plot (stored for later use)
basic_curve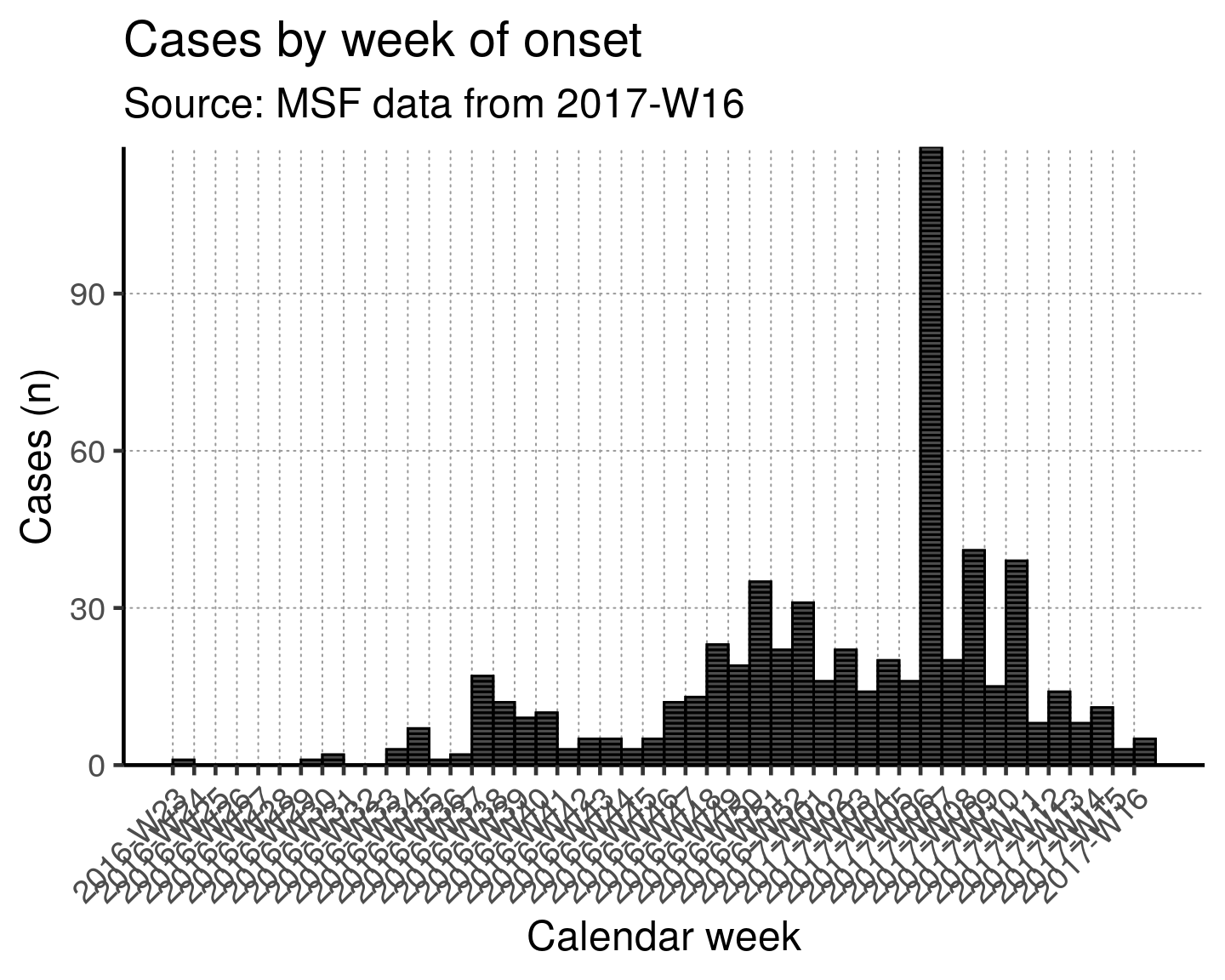
This x-axis is difficult to read with every week displayed. To increase readability we can uncomment and use the helper code at the bottom of that code chunk. This modifies the already-defined basic_curve object (with a +) to specify that the x-axis shows only a specified number of breaks/dates (in this case 6). Note: A warning that a scale for x is being replaced is okay.
The data are still shown by week - it is only the labels on the scale that have changed.
# Modifies basic_curve to show only 6 breaks in the x-axis
basic_curve + scale_x_incidence(inc_week_7, n_breaks = 6)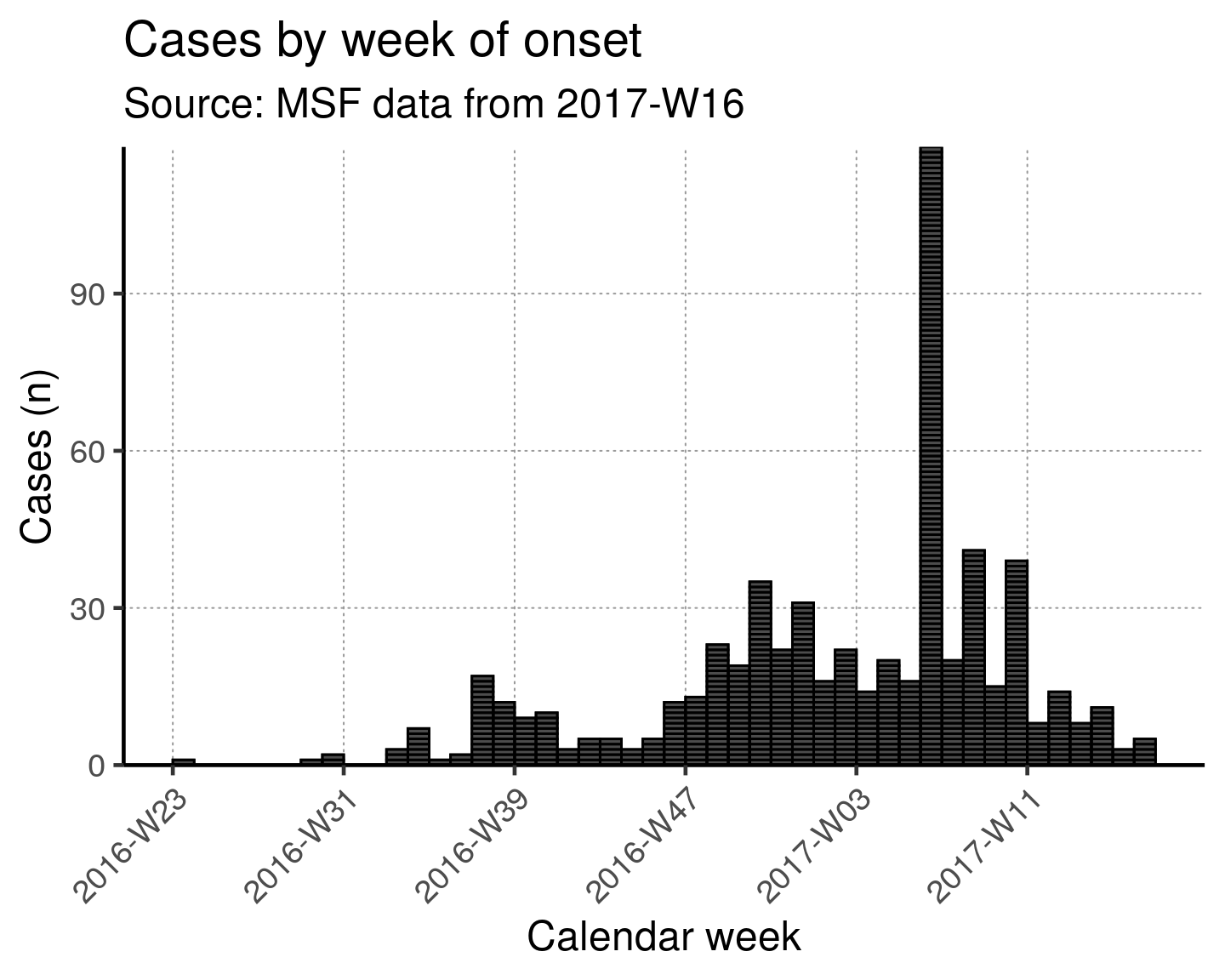
To change the intervals used for the data aggregation themselves, use the interval = argument in the original incidence() command. There are the options to do this biweekly, by month, quarter or year (search the Help pane for the incidence() function in the incidence package). Below is a biweekly example (the axes labels have been returned to default - showing each two-week increment).
In the code below, the plot is not saved to an object and simply prints when the plot() command and it’s various added (+) elements such as scale, labels, and theme are run.
# interval is set to "2 Monday weeks" for biweekly case aggregation
inc_week_14 <- incidence(linelist_cleaned$date_of_onset, interval = "2 Monday weeks")
# plot the epicurve
plot(inc_week_14, show_cases = TRUE, border = "black", n_breaks = nrow(inc_week_14)) +
scale_y_continuous(expand = c(0,0)) + # set origin for axes
# add labels to axes and below chart
epicurve_labels +
# change visuals of dates and remove legend title
epicurve_theme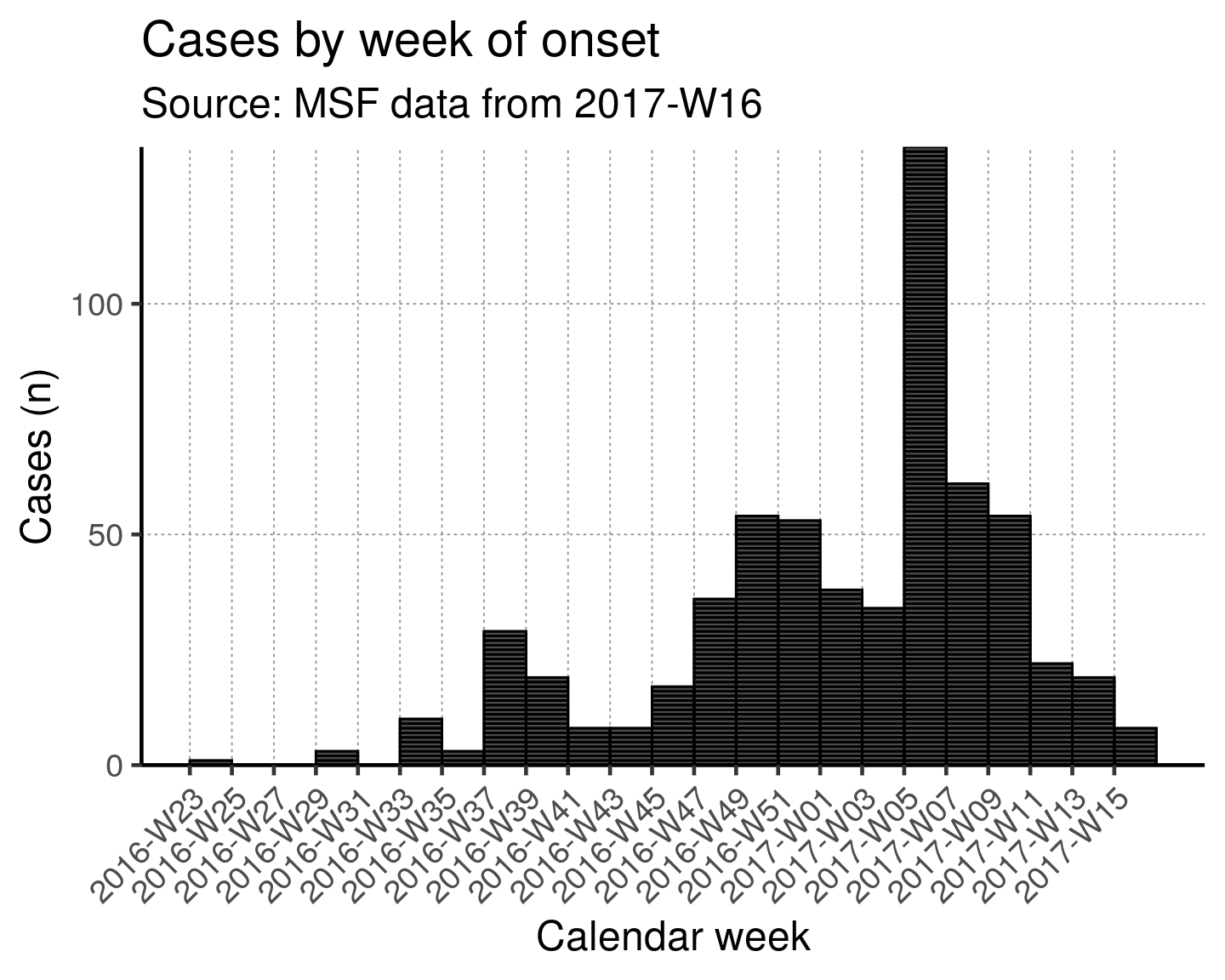
To stratify the epidemic curve by a categorical variable (such as gender), the groups = argument is added to the incidence() function. Additionally, the show_cases = argument of plot() can be set to FALSE to improve aesthetics.
Remember that if listing a variable, the incidence() function expects its “full name”, such as linelist_cleaned$sex**. Otherwise you may get an error such as “object ‘sex’ not found”.
# get counts by gender
inc_week_7_gender <- incidence(linelist_cleaned$date_of_onset,
interval = "2 Monday weeks",
groups = linelist_cleaned$sex)
# plot your epicurve
# here we remove the boxes around each case as it makes gender colours hard to see! (show_cases = FALSE)
plot(inc_week_7_gender, show_cases = FALSE, border = "black", n_breaks = nrow(inc_week_7_gender)) +
scale_y_continuous(expand = c(0,0)) + # set origin for axes
# add labels to axes and below chart
epicurve_labels +
# change visuals of dates, remove legend title and move legend to bottom
epicurve_theme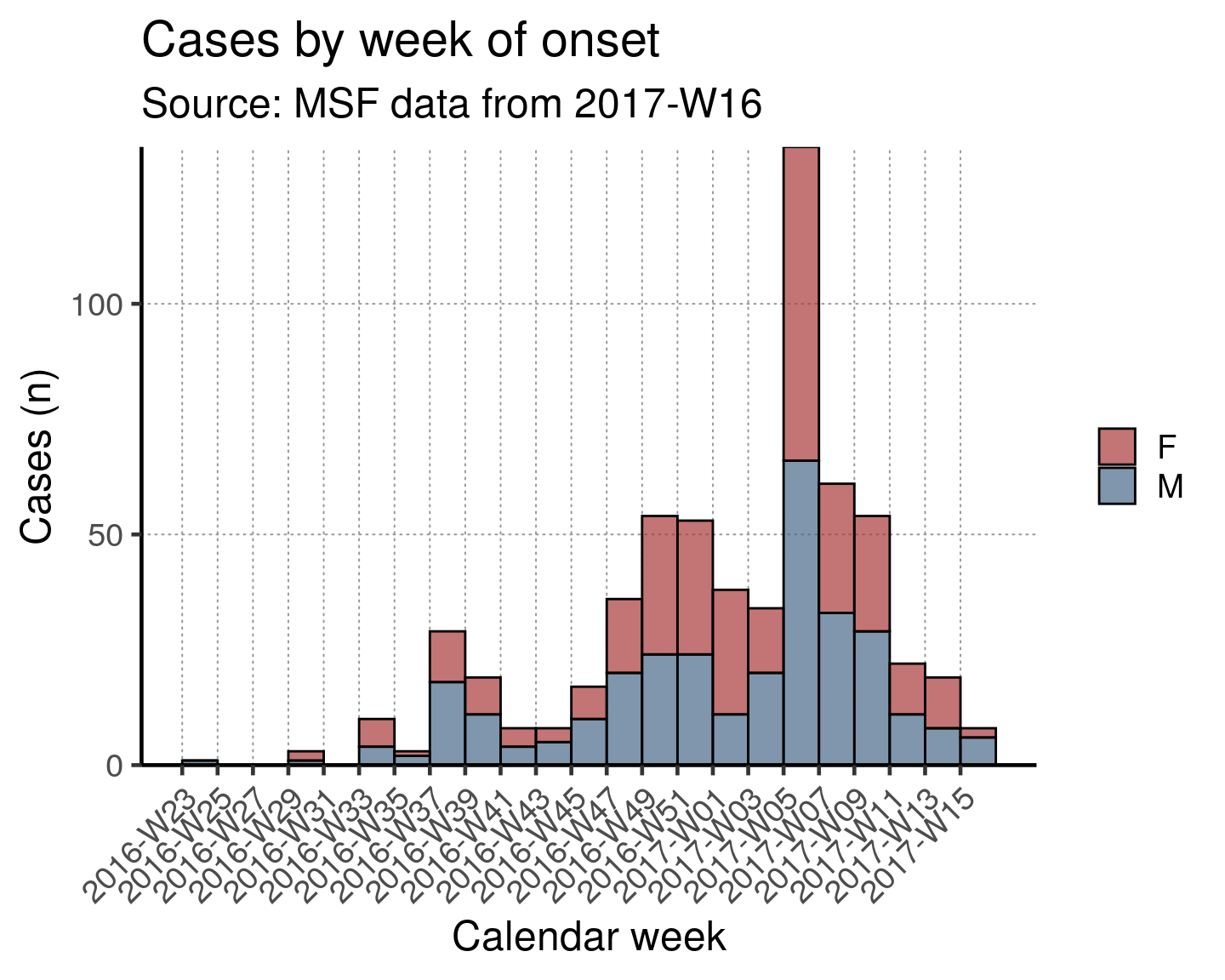
Lastly, we can limit the entire plot to a subset of observations by first filtering the dataset and passing the result to the incidence() function.
In the example below, incidence() operates upon a filtered version of linelist_cleaned that only includes inpatients. The resulting object is used, as before, in plot() in the step below.
# filter the dataset and pass it to the incidence() function
inc_week_7_sex_fac <- linelist_cleaned %>%
filter(patient_facility_type == "Inpatient") %>%
with(incidence(date_of_onset, interval = "2 Monday weeks", groups = sex))
# plot as before
plot(inc_week_7_sex_fac, show_cases = TRUE, border = "black", n_breaks = nrow(inc_week_7_sex_fac)) +
scale_y_continuous(expand = c(0, 0)) + # set origin for axes
# add labels to axes and below chart
epicurve_labels +
# change visuals of dates, remove legend title and move legend to bottom
epicurve_theme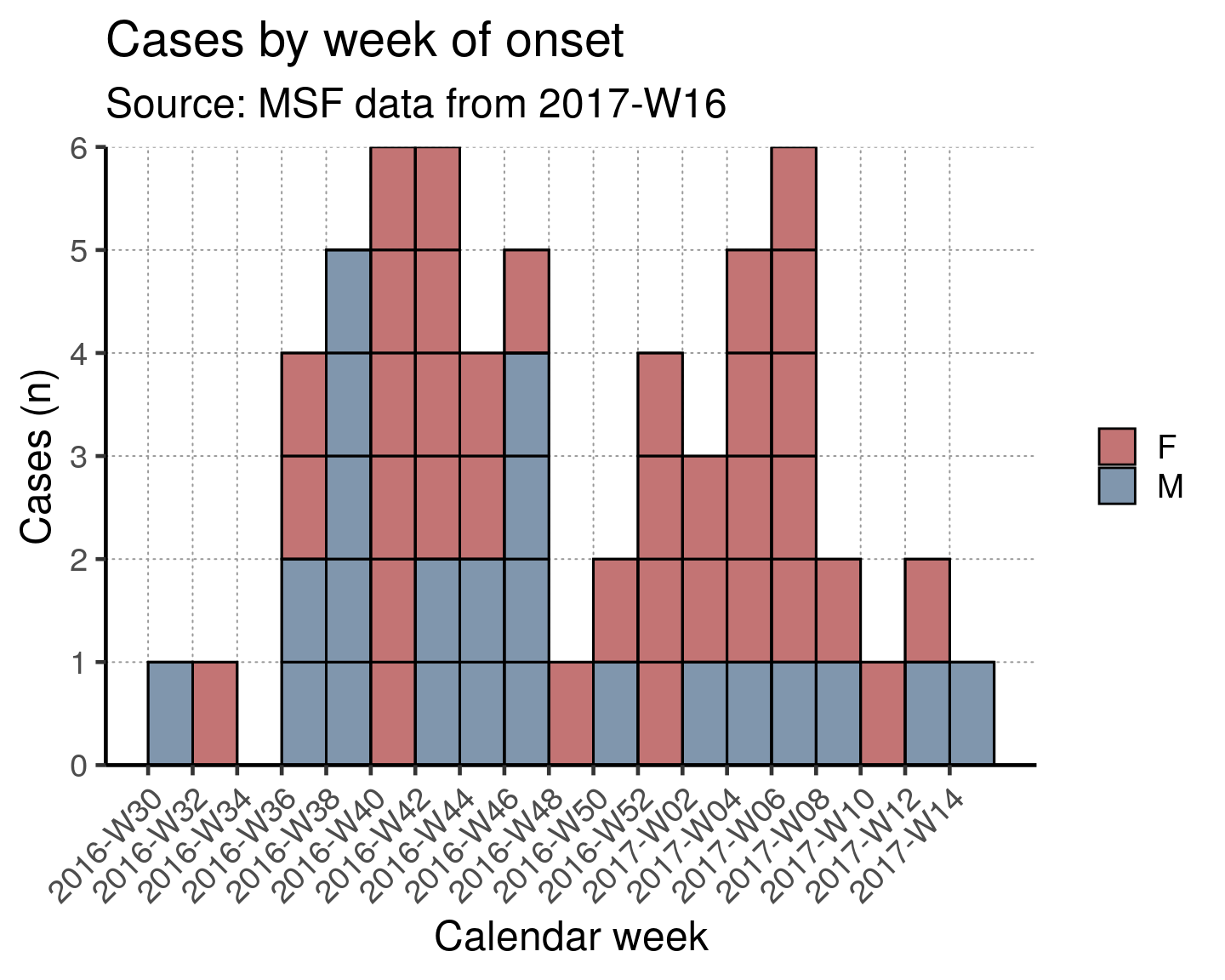
Analysis of other indicators by time
Attack rate by week
The code below produces a table of the attack rates by epiweek.
First, the object cases is defined as linelist observations counted and arranged/ordered by epiweek, accompanied by a cumulative sum column.
Second, the object ar is defined using the attack_rate() function, which looks with cases at counts for each week (column “n”) and the denominator population, which was defined earlier as the sum of the regional populations (62336). The rate multiplier is set to 10000 but is changeable. The epiweeks are also attached to ar as a column.
Third, aesthetic operations are done to ar to improve column names. Finally, the table is produced with kable().
# counts and cumulative counts by week
cases <- linelist_cleaned %>%
arrange(date_of_onset) %>% # arrange by date of onset
count(epiweek, .drop = FALSE) %>% # count all epiweeks and include zero counts
mutate(cumulative = cumsum(n)) # add a cumulative sum
# attack rate for each week
ar <- attack_rate(cases$n, population, multiplier = 10000) %>%
bind_cols(select(cases, epiweek), .) # add the epiweek column to table
# Display the table
ar %>%
merge_ci_df(e = 4) %>% # merge the lower and upper CI into one column
rename("Epiweek" = epiweek,
"Cases (n)" = cases,
"Population" = population,
"AR (per 10,000)" = ar,
"95%CI" = ci) %>%
knitr::kable(digits = 1, align = "r")| Epiweek | Cases (n) | Population | AR (per 10,000) | 95%CI |
|---|---|---|---|---|
| 2016-W23 | 1 | 62336 | 0.2 | (0.03–0.91) |
| 2016-W24 | 0 | 62336 | 0.0 | (0.00–0.62) |
| 2016-W25 | 0 | 62336 | 0.0 | (0.00–0.62) |
| 2016-W26 | 0 | 62336 | 0.0 | (0.00–0.62) |
| 2016-W27 | 0 | 62336 | 0.0 | (0.00–0.62) |
| 2016-W28 | 0 | 62336 | 0.0 | (0.00–0.62) |
| 2016-W29 | 1 | 62336 | 0.2 | (0.03–0.91) |
| 2016-W30 | 2 | 62336 | 0.3 | (0.09–1.17) |
| 2016-W31 | 0 | 62336 | 0.0 | (0.00–0.62) |
| 2016-W32 | 0 | 62336 | 0.0 | (0.00–0.62) |
| 2016-W33 | 3 | 62336 | 0.5 | (0.16–1.42) |
| 2016-W34 | 7 | 62336 | 1.1 | (0.54–2.32) |
| 2016-W35 | 1 | 62336 | 0.2 | (0.03–0.91) |
| 2016-W36 | 2 | 62336 | 0.3 | (0.09–1.17) |
| 2016-W37 | 17 | 62336 | 2.7 | (1.70–4.37) |
| 2016-W38 | 12 | 62336 | 1.9 | (1.10–3.36) |
| 2016-W39 | 9 | 62336 | 1.4 | (0.76–2.74) |
| 2016-W40 | 10 | 62336 | 1.6 | (0.87–2.95) |
| 2016-W41 | 3 | 62336 | 0.5 | (0.16–1.42) |
| 2016-W42 | 5 | 62336 | 0.8 | (0.34–1.88) |
| 2016-W43 | 5 | 62336 | 0.8 | (0.34–1.88) |
| 2016-W44 | 3 | 62336 | 0.5 | (0.16–1.42) |
| 2016-W45 | 5 | 62336 | 0.8 | (0.34–1.88) |
| 2016-W46 | 12 | 62336 | 1.9 | (1.10–3.36) |
| 2016-W47 | 13 | 62336 | 2.1 | (1.22–3.57) |
| 2016-W48 | 23 | 62336 | 3.7 | (2.46–5.54) |
| 2016-W49 | 19 | 62336 | 3.0 | (1.95–4.76) |
| 2016-W50 | 35 | 62336 | 5.6 | (4.04–7.81) |
| 2016-W51 | 22 | 62336 | 3.5 | (2.33–5.34) |
| 2016-W52 | 31 | 62336 | 5.0 | (3.50–7.06) |
| 2017-W01 | 16 | 62336 | 2.6 | (1.58–4.17) |
| 2017-W02 | 22 | 62336 | 3.5 | (2.33–5.34) |
| 2017-W03 | 14 | 62336 | 2.2 | (1.34–3.77) |
| 2017-W04 | 20 | 62336 | 3.2 | (2.08–4.96) |
| 2017-W05 | 16 | 62336 | 2.6 | (1.58–4.17) |
| 2017-W06 | 118 | 62336 | 18.9 | (15.81–22.66) |
| 2017-W07 | 20 | 62336 | 3.2 | (2.08–4.96) |
| 2017-W08 | 41 | 62336 | 6.6 | (4.85–8.92) |
| 2017-W09 | 15 | 62336 | 2.4 | (1.46–3.97) |
| 2017-W10 | 39 | 62336 | 6.3 | (4.58–8.55) |
| 2017-W11 | 8 | 62336 | 1.3 | (0.65–2.53) |
| 2017-W12 | 14 | 62336 | 2.2 | (1.34–3.77) |
| 2017-W13 | 8 | 62336 | 1.3 | (0.65–2.53) |
| 2017-W14 | 11 | 62336 | 1.8 | (0.99–3.16) |
| 2017-W15 | 3 | 62336 | 0.5 | (0.16–1.42) |
| 2017-W16 | 5 | 62336 | 0.8 | (0.34–1.88) |
| - | 825 | 62336 | 132.3 | (123.67–141.62) |
This code produces the cumulative attack rate, by week. In the attack_rate() command it references the cases$cumulative column, instead of cases$n column.
# cumulative attack rate by week
attack_rate(cases$cumulative, population, multiplier = 10000) %>%
bind_cols(select(cases, epiweek), .) %>% # add the epiweek column to table
merge_ci_df(e = 4) %>% # merge the lower and upper CI into one column
rename("Epiweek" = epiweek,
"Cases (n)" = cases,
"Population" = population,
"AR (per 10,000)" = ar,
"95%CI" = ci) %>%
knitr::kable(digits = 1, align = "r")| Epiweek | Cases (n) | Population | AR (per 10,000) | 95%CI |
|---|---|---|---|---|
| 2016-W23 | 1 | 62336 | 0.2 | (0.03–0.91) |
| 2016-W24 | 1 | 62336 | 0.2 | (0.03–0.91) |
| 2016-W25 | 1 | 62336 | 0.2 | (0.03–0.91) |
| 2016-W26 | 1 | 62336 | 0.2 | (0.03–0.91) |
| 2016-W27 | 1 | 62336 | 0.2 | (0.03–0.91) |
| 2016-W28 | 1 | 62336 | 0.2 | (0.03–0.91) |
| 2016-W29 | 2 | 62336 | 0.3 | (0.09–1.17) |
| 2016-W30 | 4 | 62336 | 0.6 | (0.25–1.65) |
| 2016-W31 | 4 | 62336 | 0.6 | (0.25–1.65) |
| 2016-W32 | 4 | 62336 | 0.6 | (0.25–1.65) |
| 2016-W33 | 7 | 62336 | 1.1 | (0.54–2.32) |
| 2016-W34 | 14 | 62336 | 2.2 | (1.34–3.77) |
| 2016-W35 | 15 | 62336 | 2.4 | (1.46–3.97) |
| 2016-W36 | 17 | 62336 | 2.7 | (1.70–4.37) |
| 2016-W37 | 34 | 62336 | 5.5 | (3.90–7.62) |
| 2016-W38 | 46 | 62336 | 7.4 | (5.53–9.84) |
| 2016-W39 | 55 | 62336 | 8.8 | (6.78–11.48) |
| 2016-W40 | 65 | 62336 | 10.4 | (8.18–13.29) |
| 2016-W41 | 68 | 62336 | 10.9 | (8.61–13.83) |
| 2016-W42 | 73 | 62336 | 11.7 | (9.32–14.72) |
| 2016-W43 | 78 | 62336 | 12.5 | (10.03–15.61) |
| 2016-W44 | 81 | 62336 | 13.0 | (10.46–16.15) |
| 2016-W45 | 86 | 62336 | 13.8 | (11.17–17.03) |
| 2016-W46 | 98 | 62336 | 15.7 | (12.90–19.15) |
| 2016-W47 | 111 | 62336 | 17.8 | (14.79–21.44) |
| 2016-W48 | 134 | 62336 | 21.5 | (18.15–25.45) |
| 2016-W49 | 153 | 62336 | 24.5 | (20.95–28.75) |
| 2016-W50 | 188 | 62336 | 30.2 | (26.15–34.78) |
| 2016-W51 | 210 | 62336 | 33.7 | (29.44–38.55) |
| 2016-W52 | 241 | 62336 | 38.7 | (34.09–43.85) |
| 2017-W01 | 257 | 62336 | 41.2 | (36.49–46.57) |
| 2017-W02 | 279 | 62336 | 44.8 | (39.81–50.31) |
| 2017-W03 | 293 | 62336 | 47.0 | (41.93–52.69) |
| 2017-W04 | 313 | 62336 | 50.2 | (44.96–56.07) |
| 2017-W05 | 329 | 62336 | 52.8 | (47.39–58.78) |
| 2017-W06 | 447 | 62336 | 71.7 | (65.38–78.64) |
| 2017-W07 | 467 | 62336 | 74.9 | (68.44–82.00) |
| 2017-W08 | 508 | 62336 | 81.5 | (74.73–88.86) |
| 2017-W09 | 523 | 62336 | 83.9 | (77.04–91.37) |
| 2017-W10 | 562 | 62336 | 90.2 | (83.03–97.89) |
| 2017-W11 | 570 | 62336 | 91.4 | (84.26–99.22) |
| 2017-W12 | 584 | 62336 | 93.7 | (86.42–101.56) |
| 2017-W13 | 592 | 62336 | 95.0 | (87.65–102.89) |
| 2017-W14 | 603 | 62336 | 96.7 | (89.35–104.73) |
| 2017-W15 | 606 | 62336 | 97.2 | (89.81–105.23) |
| 2017-W16 | 611 | 62336 | 98.0 | (90.58–106.06) |
| - | 1436 | 62336 | 230.4 | (218.88–242.44) |
This next code chunk applies a filter for only inpatient observations. It also uses a different function, case_fatality_rate_df(), to produce a table showing deaths, cases, CFR, and CFR confidence intervals.
# group by known outcome and case definition
cfr <- linelist_cleaned %>%
filter(patient_facility_type == "Inpatient") %>%
case_fatality_rate_df(grepl("Dead", exit_status), group = epiweek)
cfr %>%
merge_ci_df(e = 4) %>% # merge the lower and upper CI into one column
rename("Epiweek" = epiweek,
"Deaths" = deaths,
"Cases" = population,
"CFR (%)" = cfr,
"95%CI" = ci) %>%
knitr::kable(digits = 1, align = "r")| Epiweek | Deaths | Cases | CFR (%) | 95%CI |
|---|---|---|---|---|
| 2016-W23 | 0 | 0 | - | (NaN–NaN) |
| 2016-W24 | 0 | 0 | - | (NaN–NaN) |
| 2016-W25 | 0 | 0 | - | (NaN–NaN) |
| 2016-W26 | 0 | 0 | - | (NaN–NaN) |
| 2016-W27 | 0 | 0 | - | (NaN–NaN) |
| 2016-W28 | 0 | 0 | - | (NaN–NaN) |
| 2016-W29 | 0 | 0 | - | (NaN–NaN) |
| 2016-W30 | 0 | 1 | 0 | (0.00–79.35) |
| 2016-W31 | 0 | 0 | - | (NaN–NaN) |
| 2016-W32 | 0 | 0 | - | (NaN–NaN) |
| 2016-W33 | 0 | 1 | 0 | (0.00–79.35) |
| 2016-W34 | 0 | 0 | - | (NaN–NaN) |
| 2016-W35 | 0 | 0 | - | (NaN–NaN) |
| 2016-W36 | 0 | 0 | - | (NaN–NaN) |
| 2016-W37 | 0 | 4 | 0 | (0.00–48.99) |
| 2016-W38 | 0 | 3 | 0 | (0.00–56.15) |
| 2016-W39 | 0 | 2 | 0 | (0.00–65.76) |
| 2016-W40 | 0 | 5 | 0 | (0.00–43.45) |
| 2016-W41 | 0 | 1 | 0 | (0.00–79.35) |
| 2016-W42 | 0 | 5 | 0 | (0.00–43.45) |
| 2016-W43 | 0 | 1 | 0 | (0.00–79.35) |
| 2016-W44 | 0 | 1 | 0 | (0.00–79.35) |
| 2016-W45 | 0 | 3 | 0 | (0.00–56.15) |
| 2016-W46 | 0 | 4 | 0 | (0.00–48.99) |
| 2016-W47 | 0 | 1 | 0 | (0.00–79.35) |
| 2016-W48 | 0 | 1 | 0 | (0.00–79.35) |
| 2016-W49 | 0 | 0 | - | (NaN–NaN) |
| 2016-W50 | 0 | 1 | 0 | (0.00–79.35) |
| 2016-W51 | 0 | 1 | 0 | (0.00–79.35) |
| 2016-W52 | 0 | 2 | 0 | (0.00–65.76) |
| 2017-W01 | 0 | 2 | 0 | (0.00–65.76) |
| 2017-W02 | 0 | 1 | 0 | (0.00–79.35) |
| 2017-W03 | 0 | 2 | 0 | (0.00–65.76) |
| 2017-W04 | 0 | 4 | 0 | (0.00–48.99) |
| 2017-W05 | 0 | 1 | 0 | (0.00–79.35) |
| 2017-W06 | 0 | 5 | 0 | (0.00–43.45) |
| 2017-W07 | 0 | 1 | 0 | (0.00–79.35) |
| 2017-W08 | 0 | 1 | 0 | (0.00–79.35) |
| 2017-W09 | 0 | 1 | 0 | (0.00–79.35) |
| 2017-W10 | 0 | 1 | 0 | (0.00–79.35) |
| 2017-W11 | 0 | 0 | - | (NaN–NaN) |
| 2017-W12 | 0 | 0 | - | (NaN–NaN) |
| 2017-W13 | 0 | 2 | 0 | (0.00–65.76) |
| 2017-W14 | 0 | 1 | 0 | (0.00–79.35) |
| 2017-W15 | 0 | 0 | - | (NaN–NaN) |
| 2017-W16 | 0 | 0 | - | (NaN–NaN) |
| (Missing) | 0 | 27 | 0 | (0.00–12.46) |
Plotting AR, CFR, and Epidemic Curve together
These code chunks produce plots of the AR (in the population), CFR (among inpatients only), and the AF and CFR as line graphs together with the Epidemic Curve.
The first chunk, ar_line_graph, prepares a plot of attack rate by epiweek, but does not yet print it. You can print it alone by running a command of its name ar_plot.
This ar_plot depends on you having already run the attack_rate_per_week chunk. If you have not, you may see “Error: epiweek not found”
ar_plot <- ggplot(ar, aes(x = week2date(epiweek) + (7 * 0.5), group = 1)) +
geom_ribbon(aes(ymin = lower, ymax = upper),
color = "blue", fill = "blue", linetype = 2, alpha = 0.2, show.legend = FALSE) +
geom_line(aes(y = ar), color = "blue", show.legend = FALSE) +
scale_y_continuous(expand = c(0, 0)) + # set origin for axes
# scale the x axis the same as the incidence curve. Expand forces it to align.
incidence::scale_x_incidence(inc_week_7, n_breaks = nrow(inc_week_7), expand = c(0, 7 * 1.5)) +
# add labels to axes and below chart
labs(x = "Calendar week", y = "AR [95% CI]", subtitle = "Attack Rate (per 10,000)") +
# change visuals of dates and remove legend title
epicurve_themeThe second code chunk, cfr_line_graph prepares a plot of CFR by epiweek, but also does not yet print it. You can print it alone by running a command with its name cfr_plot.
This cfr_plot depends on you having already run the cfr_per_week chunk. If you have not, you may see “Error: epiweek not found”.
cfr_plot <- ggplot(cfr, aes(x = week2date(epiweek) + (7 * 0.5), group = 1)) +
geom_ribbon(aes(ymin = lower, ymax = upper),
color = "red", fill = "red", linetype = 2, alpha = 0.2, show.legend = FALSE) +
geom_line(aes(y = cfr), color = "red", show.legend = FALSE) +
scale_y_continuous(expand = c(0, 0)) + # set origin for axes
# scale the x axis the same as the incidence curve. Expand forces it to align.
incidence::scale_x_incidence(inc_week_7, n_breaks = nrow(inc_week_7), expand = c(0, 7 * 1.5)) +
# add labels to axes and below chart
labs(x = "Calendar week", y = "CFR [95% CI]",
subtitle = "Case Fatality Ratio [95% CI] Among Inpatients") +
# change visuals of dates and remove legend title
epicurve_theme Adding the AR and CFR plots with an Epidemic Curve (chunk epicurve_ar_cfr) and plotting them all together is now possible with the function cowplot(), which nicely combines different plots. You can read more about cowplot() in the Advanced and Miscellaneous R Basics page.
# Define no specified axis text or title over the combined plot
nofx <- theme(axis.text.x = element_blank(),
axis.title.x = element_blank())
# Combine the three plots together
cowplot::plot_grid(
basic_curve + nofx,
ar_plot + nofx,
cfr_plot,
align = "v", # align plots vertically
axis = "lr", # only by their left and right margins
ncol = 1 # allow only one column
)## Error in stop_if_not_aweek_string(x): aweek strings must match the pattern 'YYYY-Www-d'. The first incorrect string was: '(Missing)'Admission and exits by epiweek
This next code chunk describes each epiweek’s admission by their case definition status. It uses tab_linelist() again to look at linelist_cleaned, with rows as epiweek, and columns as case_def, with row and column totals.
# get counts and props of admissions by epiweek and case definition
# include column and row totals
tab_linelist(linelist_cleaned, epiweek, strata = case_def,
col_total = TRUE,
row_total = TRUE) %>%
select(-variable) %>%
rename_redundant("%" = proportion) %>%
augment_redundant(" (n)" = " n$") %>%
kable(digits = 1)| value | Confirmed (n) | % | Probable (n) | % | Suspected (n) | % | Missing (n) | % | Total |
|---|---|---|---|---|---|---|---|---|---|
| 2016-W23 | 1 | 1.4 | 0 | 0 | 0 | 0.0 | 0 | 0.0 | 1 |
| 2016-W29 | 0 | 0.0 | 0 | 0 | 1 | 0.2 | 0 | 0.0 | 1 |
| 2016-W30 | 1 | 1.4 | 0 | 0 | 0 | 0.0 | 1 | 3.6 | 2 |
| 2016-W33 | 1 | 1.4 | 1 | 25 | 1 | 0.2 | 0 | 0.0 | 3 |
| 2016-W34 | 0 | 0.0 | 0 | 0 | 2 | 0.4 | 5 | 17.9 | 7 |
| 2016-W35 | 0 | 0.0 | 0 | 0 | 1 | 0.2 | 0 | 0.0 | 1 |
| 2016-W36 | 1 | 1.4 | 0 | 0 | 1 | 0.2 | 0 | 0.0 | 2 |
| 2016-W37 | 9 | 12.9 | 0 | 0 | 8 | 1.6 | 0 | 0.0 | 17 |
| 2016-W38 | 5 | 7.1 | 0 | 0 | 5 | 1.0 | 2 | 7.1 | 12 |
| 2016-W39 | 2 | 2.9 | 0 | 0 | 3 | 0.6 | 4 | 14.3 | 9 |
| 2016-W40 | 4 | 5.7 | 0 | 0 | 3 | 0.6 | 3 | 10.7 | 10 |
| 2016-W41 | 1 | 1.4 | 0 | 0 | 0 | 0.0 | 2 | 7.1 | 3 |
| 2016-W42 | 2 | 2.9 | 0 | 0 | 3 | 0.6 | 0 | 0.0 | 5 |
| 2016-W43 | 1 | 1.4 | 0 | 0 | 3 | 0.6 | 1 | 3.6 | 5 |
| 2016-W44 | 0 | 0.0 | 0 | 0 | 3 | 0.6 | 0 | 0.0 | 3 |
| 2016-W45 | 2 | 2.9 | 0 | 0 | 3 | 0.6 | 0 | 0.0 | 5 |
| 2016-W46 | 2 | 2.9 | 0 | 0 | 8 | 1.6 | 2 | 7.1 | 12 |
| 2016-W47 | 0 | 0.0 | 0 | 0 | 10 | 2.0 | 3 | 10.7 | 13 |
| 2016-W48 | 2 | 2.9 | 0 | 0 | 20 | 3.9 | 1 | 3.6 | 23 |
| 2016-W49 | 0 | 0.0 | 1 | 25 | 18 | 3.5 | 0 | 0.0 | 19 |
| 2016-W50 | 2 | 2.9 | 0 | 0 | 30 | 5.9 | 3 | 10.7 | 35 |
| 2016-W51 | 3 | 4.3 | 0 | 0 | 19 | 3.7 | 0 | 0.0 | 22 |
| 2016-W52 | 4 | 5.7 | 0 | 0 | 26 | 5.1 | 1 | 3.6 | 31 |
| 2017-W01 | 3 | 4.3 | 0 | 0 | 13 | 2.6 | 0 | 0.0 | 16 |
| 2017-W02 | 1 | 1.4 | 0 | 0 | 21 | 4.1 | 0 | 0.0 | 22 |
| 2017-W03 | 1 | 1.4 | 1 | 25 | 12 | 2.4 | 0 | 0.0 | 14 |
| 2017-W04 | 3 | 4.3 | 1 | 25 | 16 | 3.1 | 0 | 0.0 | 20 |
| 2017-W05 | 3 | 4.3 | 0 | 0 | 13 | 2.6 | 0 | 0.0 | 16 |
| 2017-W06 | 9 | 12.9 | 0 | 0 | 109 | 21.4 | 0 | 0.0 | 118 |
| 2017-W07 | 1 | 1.4 | 0 | 0 | 19 | 3.7 | 0 | 0.0 | 20 |
| 2017-W08 | 3 | 4.3 | 0 | 0 | 38 | 7.5 | 0 | 0.0 | 41 |
| 2017-W09 | 0 | 0.0 | 0 | 0 | 15 | 2.9 | 0 | 0.0 | 15 |
| 2017-W10 | 1 | 1.4 | 0 | 0 | 38 | 7.5 | 0 | 0.0 | 39 |
| 2017-W11 | 0 | 0.0 | 0 | 0 | 8 | 1.6 | 0 | 0.0 | 8 |
| 2017-W12 | 1 | 1.4 | 0 | 0 | 13 | 2.6 | 0 | 0.0 | 14 |
| 2017-W13 | 1 | 1.4 | 0 | 0 | 7 | 1.4 | 0 | 0.0 | 8 |
| 2017-W14 | 0 | 0.0 | 0 | 0 | 11 | 2.2 | 0 | 0.0 | 11 |
| 2017-W15 | 0 | 0.0 | 0 | 0 | 3 | 0.6 | 0 | 0.0 | 3 |
| 2017-W16 | 0 | 0.0 | 0 | 0 | 5 | 1.0 | 0 | 0.0 | 5 |
| Total | 70 | 100.0 | 4 | 100 | 509 | 100.0 | 28 | 100.0 | 611 |
Finally, this produces the same table as above but uses exit_status2 as the strata/column variable to display exits per epiweek. Note that this is also filtered to only include inpatient observations.
# get counts and props of admissions by epiweek among inpatients
# include column and row totals
linelist_cleaned %>%
filter(patient_facility_type == "Inpatient") %>%
tab_linelist(epiweek, strata = exit_status2,
col_total = TRUE, row_total = TRUE) %>%
select(-variable) %>%
rename("Week" = value) %>%
rename_redundant("%" = proportion) %>%
augment_redundant(" (n)" = " n$") %>%
kable(digits = 1)| Week | Dead (n) | % | Discharged (n) | % | Left (n) | % | Missing (n) | % | Total |
|---|---|---|---|---|---|---|---|---|---|
| 2016-W30 | 0 | 0.0 | 0 | 0.0 | 0 | 0 | 1 | 7.1 | 1 |
| 2016-W33 | 0 | 0.0 | 1 | 2.9 | 0 | 0 | 0 | 0.0 | 1 |
| 2016-W37 | 0 | 0.0 | 2 | 5.7 | 0 | 0 | 2 | 14.3 | 4 |
| 2016-W38 | 1 | 12.5 | 2 | 5.7 | 0 | 0 | 0 | 0.0 | 3 |
| 2016-W39 | 0 | 0.0 | 2 | 5.7 | 0 | 0 | 0 | 0.0 | 2 |
| 2016-W40 | 1 | 12.5 | 4 | 11.4 | 0 | 0 | 0 | 0.0 | 5 |
| 2016-W41 | 0 | 0.0 | 0 | 0.0 | 1 | 50 | 0 | 0.0 | 1 |
| 2016-W42 | 2 | 25.0 | 1 | 2.9 | 0 | 0 | 2 | 14.3 | 5 |
| 2016-W43 | 0 | 0.0 | 0 | 0.0 | 0 | 0 | 1 | 7.1 | 1 |
| 2016-W44 | 0 | 0.0 | 0 | 0.0 | 0 | 0 | 1 | 7.1 | 1 |
| 2016-W45 | 2 | 25.0 | 0 | 0.0 | 0 | 0 | 1 | 7.1 | 3 |
| 2016-W46 | 0 | 0.0 | 3 | 8.6 | 0 | 0 | 1 | 7.1 | 4 |
| 2016-W47 | 0 | 0.0 | 0 | 0.0 | 0 | 0 | 1 | 7.1 | 1 |
| 2016-W48 | 0 | 0.0 | 0 | 0.0 | 0 | 0 | 1 | 7.1 | 1 |
| 2016-W50 | 0 | 0.0 | 1 | 2.9 | 0 | 0 | 0 | 0.0 | 1 |
| 2016-W51 | 0 | 0.0 | 0 | 0.0 | 0 | 0 | 1 | 7.1 | 1 |
| 2016-W52 | 1 | 12.5 | 0 | 0.0 | 0 | 0 | 1 | 7.1 | 2 |
| 2017-W01 | 0 | 0.0 | 1 | 2.9 | 1 | 50 | 0 | 0.0 | 2 |
| 2017-W02 | 0 | 0.0 | 1 | 2.9 | 0 | 0 | 0 | 0.0 | 1 |
| 2017-W03 | 0 | 0.0 | 2 | 5.7 | 0 | 0 | 0 | 0.0 | 2 |
| 2017-W04 | 0 | 0.0 | 4 | 11.4 | 0 | 0 | 0 | 0.0 | 4 |
| 2017-W05 | 0 | 0.0 | 0 | 0.0 | 0 | 0 | 1 | 7.1 | 1 |
| 2017-W06 | 0 | 0.0 | 5 | 14.3 | 0 | 0 | 0 | 0.0 | 5 |
| 2017-W07 | 1 | 12.5 | 0 | 0.0 | 0 | 0 | 0 | 0.0 | 1 |
| 2017-W08 | 0 | 0.0 | 1 | 2.9 | 0 | 0 | 0 | 0.0 | 1 |
| 2017-W09 | 0 | 0.0 | 1 | 2.9 | 0 | 0 | 0 | 0.0 | 1 |
| 2017-W10 | 0 | 0.0 | 1 | 2.9 | 0 | 0 | 0 | 0.0 | 1 |
| 2017-W13 | 0 | 0.0 | 2 | 5.7 | 0 | 0 | 0 | 0.0 | 2 |
| 2017-W14 | 0 | 0.0 | 1 | 2.9 | 0 | 0 | 0 | 0.0 | 1 |
| Total | 8 | 100.0 | 35 | 100.0 | 2 | 100 | 14 | 100.0 | 59 |